 うまサイエンス
うまサイエンス 
はじめまして!さかなちゃんです!
「競馬予想AIモデルを自力で作ってみたい!」「予想を自動化させたい!」
データサイエンスに興味を持っている方の中には、競馬予測モデルを作成してみたいと考える方も多いでしょう。(競馬予想モデル作成についてはこちら)
しかし、初心者にとっては、いきなり競馬のような複雑なデータを扱うのは難しいかもしれません。
そこで、まずはデータサイエンスの基礎を学ぶために、Kaggleで提供されているタイタニック問題に挑戦してみましょう!
この問題は、データの理解や分析、そして予測モデルの作成における基本的なスキルを習得するのに最適です。
タイタニック号の乗客データを使って、生存者を予測するこの課題を通じて、データサイエンスの第一歩を踏み出しましょう!
-
- データサイエンスの分野に興味がある!
- 競馬予想を自動化させたい!
- とりあえずデータサイエンスを実践してみたい!
①タイタニック問題とは?

Kaggleを知っている方にとっては有名な「タイタニック問題」について説明いたします。
Kaggleは、データサイエンスのコミュニティであり、さまざまなデータセットや機械学習の課題に取り組むことができるプラットフォームです。
初心者から上級者まで、スキルレベルに応じたコンペティションや課題が用意されており、学びながら実践的なスキルを磨くことができます。
Kaggleは、データサイエンスの世界に足を踏み入れるための絶好の機会を提供してくれます。
簡単にアカウント登録でき、今回のタイタニック問題のデータもダウンロード出来ますよ!
タイタニック問題は、Kaggleで最も有名で初心者に人気のある課題の一つです。
この問題では、1912年に起こったタイタニック号沈没事故に関するデータセットを使用し、乗客の生存を予測することが目的となります。
データセットには、乗客の年齢、性別、乗船クラス、チケットの料金などの情報が含まれており、これらのデータを基にして、生存者を予測するモデルを作成します。
タイタニック問題を解くことで、データサイエンスの基礎を学ぶことができます。
まず、データセットの中から不要なデータや欠損値を取り除く「データクリーニング」のスキルを習得します。
次に、予測モデルの精度を高めるために重要なデータ項目(特徴量)を選択する「特徴量選択」の考え方を学びます。
最後に、選択した特徴量を用いて、実際に予測モデルを構築し、そのモデルを評価する方法を学ぶことができます。
この一連のプロセスを通じて、データサイエンスの基本的な流れを体験できるため、初心者にとって最適な学習素材となります。
②データの理解と前処理

予測モデルを作るためには、どのような情報を持っているのか知ることが大切です!
タイタニックデータセットには、乗客に関するさまざまな情報が含まれていますが、その中でも特に生存率に大きく影響を与える特徴量があります。
代表的なものとして「年齢」「性別」「乗船クラス」が挙げられます。
- 年齢: 年齢は生存率に大きな影響を与える要素の一つです。一般的に、子供や若い人が優先的に救助されることが多いため、年齢が若いほど生存率が高い傾向があります。
- 性別: タイタニック号の沈没では、「女性と子供が優先的に救命ボートに乗せられた」という歴史的背景があるため、性別は非常に重要な特徴量です。実際、女性の生存率は男性よりも高くなっています。
- 乗船クラス: 乗船クラスは、1等、2等、3等の3つに分かれており、これも生存率に大きく影響します。1等船室に乗っていた乗客は救助される可能性が高く、3等船室の乗客の生存率は低い傾向にあります。
これらの特徴量を理解することで、生存率にどのような要因が影響を与えるのかが見えてきます。
この理解は、予測モデルを作成する際に非常に重要です。
現実のデータには、しばしば「欠損値」という問題があります。
欠損値とは、あるべきデータが抜け落ちている状態のことで、例えば「年齢」が記録されていない乗客がいる場合などがこれに該当します。
欠損値が存在するままでは、モデルが正確な予測を行うことが難しくなるため、適切な処理が必要です。
欠損値の処理方法はいくつかありますが、初心者の方には以下の方法がおすすめです。
- 補完(Imputation): 欠損しているデータを、平均値や中央値、最頻値で埋める方法です。例えば、年齢の欠損値がある場合、その列の他の乗客の年齢の中央値を使って埋めることができます。
- 削除: 欠損値が多い列や、分析にほとんど影響を与えない列は削除することも選択肢の一つです。ただし、重要な情報を含む列を削除しないよう注意が必要です。
また、データには予測に直接関係しない情報も含まれていることがあります。
例えば、乗客の「名前」や「チケット番号」は、生存予測に直接関わることは少ないため、これらの列は削除しても問題ありません。
これを「データクリーニング」と呼び、モデルが正確な予測を行うための重要なステップです。
ここでは、Pythonを使ってタイタニックデータセットを前処理する例を示します。初心者の方でも分かりやすいように、コードとその解説を合わせて紹介します。
import pandas as pd
# タイタニックデータセットを読み込む
titanic_data = pd.read_csv('titanic.csv')
# 欠損値の確認
print(titanic_data.isnull().sum())
# 年齢の欠損値を中央値で補完
titanic_data['Age'].fillna(titanic_data['Age'].median(), inplace=True)
# 性別と乗船クラスのダミー変数を作成
titanic_data = pd.get_dummies(titanic_data, columns=['Sex', 'Pclass'], drop_first=True)
# 不要な列の削除
titanic_data.drop(columns=['Name', 'Ticket', 'Cabin'], inplace=True)
# 前処理が完了したデータの確認
print(titanic_data.head())-
- データの読み込み: pd.read_csv関数を使って、タイタニックデータセットを読み込みます。
- 欠損値の確認: isnull().sum()を使って、どの列に欠損値があるかを確認します。これにより、どのデータに処理が必要かを特定できます。
- 欠損値の補完: fillna関数を使って、「年齢」の欠損値を年齢列の中央値で補完します。中央値を使うことで、極端な値による影響を避けることができます。
- ダミー変数の作成: get_dummies関数を使って、カテゴリカルデータ(「性別」や「乗船クラス」)をモデルが処理しやすい数値データに変換します。これにより、性別やクラスがモデルに影響を与えるようになります。
- 不要な列の削除: drop関数を使って、予測に直接関係しない「名前」「チケット番号」「船室番号」の列を削除します。
このような前処理を行うことで、データがモデルにとって理解しやすくなり、より正確な予測ができるようになります。
前処理はデータサイエンスの基本中の基本であり、このプロセスをしっかり理解することが、競馬予測モデルの作成にも役立ちます。
③モデル作成と予測

様々な機械学習モデルで学習させてみましょう!
まず、初心者にとって取り組みやすいアルゴリズムとしてロジスティック回帰を紹介します。
ロジスティック回帰は、データの特徴量を基に、特定のイベント(この場合、生存するか否か)の発生確率を予測するための手法です。
このアルゴリズムは非常にシンプルで、モデルの結果を解釈しやすいのが特徴です。
以下のコード例では、前処理済みのタイタニックデータを使ってロジスティック回帰モデルを構築し、生存者を予測しています。
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# 特徴量とターゲット変数を分ける
X = titanic_data.drop(columns=['Survived'])
y = titanic_data['Survived']
# データをトレーニングセットとテストセットに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# ロジスティック回帰モデルの作成とトレーニング
model = LogisticRegression(max_iter=200)
model.fit(X_train, y_train)
# テストセットで予測を行う
y_pred = model.predict(X_test)
# モデルの精度を評価
accuracy = accuracy_score(y_test, y_pred)
print(f'ロジスティック回帰モデルの正解率: {accuracy:.2f}')-
- ロジスティック回帰は、シンプルかつ効果的な二値分類手法です。
- このモデルでは、乗客の特徴に基づいて生存の確率を計算し、その確率に基づいて「生存」か「死亡」を予測します。
- 正解率は、予測がどれだけ正確かを示す指標で、初学者でも理解しやすい評価基準です。
次に、もう少し直感的に理解しやすい決定木というアルゴリズムを紹介します。
決定木は、特徴量の値に基づいてデータを分岐させ、最終的に予測結果を導き出します。
これは、木構造で表現されるため、どの特徴量が予測にどのように影響しているかが視覚的に分かりやすいのが特徴です。
from sklearn.tree import DecisionTreeClassifier
# 決定木モデルの作成とトレーニング
tree_model = DecisionTreeClassifier(random_state=42)
tree_model.fit(X_train, y_train)
# テストセットで予測を行う
y_pred_tree = tree_model.predict(X_test)
# モデルの精度を評価
accuracy_tree = accuracy_score(y_test, y_pred_tree)
print(f'決定木モデルの正解率: {accuracy_tree:.2f}')-
- 決定木は、各特徴量に基づいてデータを「はい/いいえ」で分けるプロセスを繰り返し、最終的に予測を行います。
- 決定木の利点は、モデルがどうしてその予測を行ったのかを可視化できる点にあります。これにより、モデルの動作を直感的に理解しやすくなります。
最後に、もう少し高度な手法としてランダムフォレストを紹介します。
ランダムフォレストは、複数の決定木を使って多数決を行うアンサンブル学習の一種です。
これにより、個々の決定木が持つ弱点を補い、全体的な予測精度を向上させることができます。
from sklearn.ensemble import RandomForestClassifier
# ランダムフォレストモデルの作成とトレーニング
forest_model = RandomForestClassifier(n_estimators=100, random_state=42)
forest_model.fit(X_train, y_train)
# テストセットで予測を行う
y_pred_forest = forest_model.predict(X_test)
# モデルの精度を評価
accuracy_forest = accuracy_score(y_test, y_pred_forest)
print(f'ランダムフォレストモデルの正解率: {accuracy_forest:.2f}')-
- ランダムフォレストは、複数の決定木を組み合わせることで、予測のばらつきを減らし、より安定した結果を得ることができます。
- 特にデータにノイズが多い場合や、過剰適合を防ぎたい場合に有効です。
- ハイパーパラメータの調整として、n_estimators(決定木の数)を増やすことで、モデルの精度をさらに向上させることができます。
各モデルの予測結果を評価するためには、正解率や精度(precision)、再現率(recall)といった指標を使うことが一般的です。
初めての方は、まずは正解率に注目してみてください。
正解率が高いモデルは、全体として多くの正解を予測できていることを意味します。
さらに、予測精度を上げるためには、ハイパーパラメータの調整が効果的です。
例えば、ランダムフォレストのn_estimatorsを増やすことで、モデルの予測精度が向上する可能性があります。
また、クロスバリデーションを使ってモデルを評価することで、より安定した予測性能を確認することができます。
このように、異なる機械学習アルゴリズムを使ってタイタニックデータセットを分析し、生存者を予測することで、データサイエンスの基本的なスキルを習得できます。
自分に合ったモデルを選び、少しずつ改良していくプロセスは、実際の競馬予測モデルを作成する際にも大いに役立つでしょう。
④結果の解釈と次のステップ

タイタニック問題でデータサイエンスの概要をつかんだら、次は自分の好きなものを分析してみましょう!
モデルが予測した結果を解釈することは、データサイエンスにおいて非常に重要です。
これを行うことで、どの特徴量が生存率に大きく影響を与えているかを理解できます。
たとえば、ランダムフォレストモデルを使用した場合、各特徴量の重要度を計算することができます。
import matplotlib.pyplot as plt
# 特徴量の重要度を取得
importances = forest_model.feature_importances_
features = X_train.columns
# 重要度を視覚化
plt.figure(figsize=(10, 6))
plt.barh(features, importances)
plt.xlabel('特徴量の重要度')
plt.ylabel('特徴量')
plt.title('特徴量の重要度ランキング')
plt.show()このコードでは、モデルがどの特徴量に最も依存して予測を行ったかを視覚化しています。
性別や乗船クラスが生存率に大きく影響を与えていることがグラフで確認できるでしょう。
特に、性別が高い重要度を持っている場合、モデルは「女性の方が生存しやすい」という事実をしっかり捉えていることが分かります。
以下はモデル評価図の一例です。
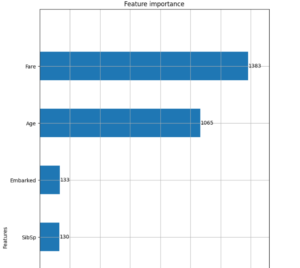
タイタニック問題を通じて、データの前処理、特徴量選択、モデル作成、そして結果の解釈といったデータサイエンスの基本を学んだ今、競馬予測モデルの作成に挑戦するための基礎が固まったといえます。
競馬に興味がない方も、ぜひこちらを閲覧してください。
また、もっとスキルを磨きたい!という方はぜひこの書籍がおすすめです!

これまでに学んだスキルは、実際の競馬予測にも大いに役立つでしょう。
たとえば、馬の成績データや騎手の過去のパフォーマンスを分析する際に、今回学んだ前処理の技術や特徴量選択の考え方が応用できます。
競馬予測モデルを作成する際、タイタニック問題で学んだ知識を以下のように応用できます。
-
- 特徴量選択: 競馬予測では、馬の過去成績、騎手の実力、コースの特性などが重要な特徴量となります。タイタニック問題で学んだように、これらの特徴量が予測にどのように影響するかを分析し、重要度を評価することで、より精度の高いモデルを構築できます。
- モデル作成と評価: 競馬データを用いて、ロジスティック回帰やランダムフォレストといった機械学習アルゴリズムを適用することが可能です。タイタニック問題で使った評価方法(正解率やAUCスコアなど)をそのまま競馬予測に適用し、モデルの性能を評価しましょう。
- ハイパーパラメータの調整: 競馬予測モデルの精度をさらに高めるために、ハイパーパラメータの調整を行います。ランダムフォレストのn_estimators<やmax_depthを調整し、モデルのパフォーマンスを最適化しましょう。
次のステップとしては、競馬のデータを集め、これまでに学んだ手法を実際に適用してみることです。
タイタニック問題で得た知識を土台にして、今度は競馬予測モデルの作成にチャレンジしましょう。
データサイエンスの学びを進めていく中で、さらに高度な分析手法やモデルを習得し、競馬予測の精度をどんどん向上させることができるでしょう。
⑤まとめ
それでは、今回の内容をおさらいします。
- タイタニック問題でデータサイエンスの基本を学ぶ重要性
- 学んだスキルが競馬予測モデル作成に役立つことを強調
- 次回以降、データサイエンス技術をさらに深く掘り下げる予定
タイタニック問題を通じて、データサイエンスの基礎を学ぶことができました。
データの前処理や特徴量選択、モデル作成といった基本的なスキルを身につけたことで、次に取り組む競馬予測モデルの作成もスムーズに進められるでしょう。
データサイエンスの基礎をしっかり理解することで、複雑な問題にも自信を持って取り組むことができます。
