 うまサイエンス
うまサイエンス はじめまして!さかなちゃんです!
「競馬予想AIモデルを自力で作ってみたい!」「予想を自動化させたい!」
こう考える人は多いですが、いざやってみようと思うとデータの集め方がわからなかったり、そもそも機械学習モデルってなに、、、となり、結構ハードルが高く、挫折してしまう方も多いのではないでしょうか。
かく言う私さかなちゃんもそのうちの一人で、何度も挑戦&挫折を繰り返し、ようやくモデルを作れるようになりました!
そんな経験を活かして、今回はプログラミング初心者の方でも競馬予想モデルを作れるように、簡単に取り組めるAI競馬予測モデルの作成方法を紹介します!
データの収集から特徴量の作成、モデルの構築まで、初心者にも分かりやすく説明し、実際のコードも公開するのでぜひご覧になってください!
-
- データサイエンスの分野に興味がある!
- 競馬予想を自動化させたい!
- 競馬予想モデルを作りたい!
-
- Googleアカウント
- PC(スマホでもできなくはないけど操作難しいかも、、)
①環境構築が超簡単!Google Colabを使おう!

そもそもプログラミングは環境構築がめんどくさいんですよね。
競馬AI予測モデルを作成するためにも、まずは実行環境を整える必要があります。
そこで、今回はGoogle Colabという無料のオンライン環境を使うことで、手軽に環境を整え、すぐに作業を開始しましょう!
Google Colabなら、ブラウザだけで簡単にプログラムを実行できます。
まずはGoogle Colabの使い方を覚えて、手軽に始めてみましょう!
Google Colabを使うために特別なソフトウェアをインストールする必要はありません。
以下のステップに従うだけで、すぐに利用を開始できます。
Google ColabはGoogleのサービスなので、Googleアカウントが必要です。すでに持っている場合はログインしましょう。アカウントを持っていない場合は、無料で作成できます。
Google Driveはオンライン上にファイルを保存できるストレージサービスです。
今回はここにファイルを保存して、モデル作成を進めたいと思います!
プロフィールアイコン横のメニューからドライブを選択してみましょう!
上手く探せない方は、Google Driveで検索するとログインできます。

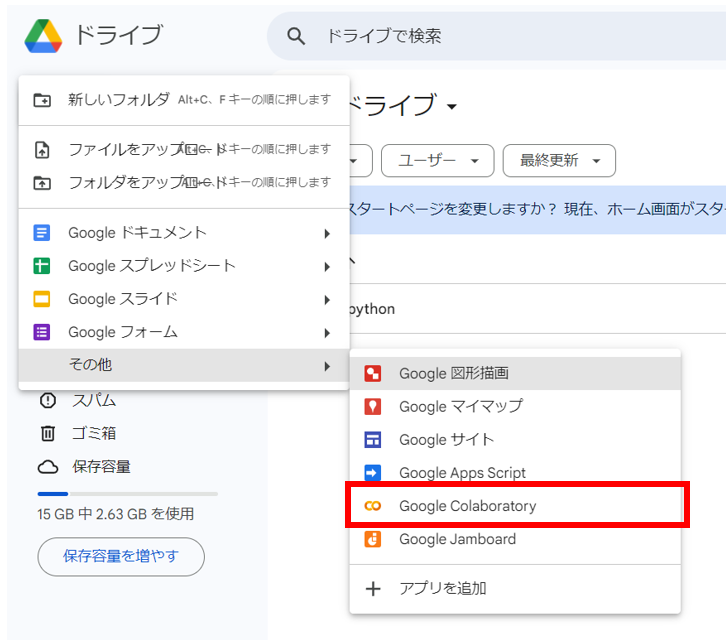
ログイン出来たらさっそくGoogle Colabを開いてみましょう。
左上の「新規」から「その他」の欄を選択すると、Google Colabが出てきます。
もしGoogle Colabがない方は「その他」を選択した下にある「アプリの追加」からGoogle Colabを追加してください。
これであとはコードを書いて実行できます!
Google Colabを使うと、多くのメリットがあります。
特に初学者にとっては、以下の点が非常に便利です。
-
- 無料で使える: ColabはGoogleが提供する無料のサービスです。高価なソフトウェアやハードウェアを購入する必要がなく、すぐに始められます。
- クラウド上での実行: すべての処理はGoogleのクラウド上で行われるため、PCの性能に依存せず、高速な計算が可能です。これにより、大量のデータを扱うAIモデルでもスムーズに動作します。
- コードの共有とコラボレーションが簡単: Colabでは、作成したノートブックを他のユーザーと簡単に共有できます。リンクを送るだけで、友達や同僚と一緒にコードを書いたり、結果を確認したりすることができます。
②競馬予測に必要なデータを手に入れよう!

競馬AI予測モデルを作成するためには、まず予測に必要なデータを集めることが重要です。
今回使用するのは、競馬情報サイトとして有名なnetkeibaです。
ここから過去のレース結果や馬の情報をスクレイピングしてデータを取得します。
スクレイピングとは、ウェブサイトからデータを自動的に収集する手法のことです。
初心者の方でも簡単に実行できるので、ぜひ試してみましょう!
この例では、過去10年の有馬記念の結果と出走馬の成績を取得する方法を示します。
また、サーバーに過度な負荷をかけないようにリクエストの間隔を空けるなどの配慮が必要です。(下記コードは対策済みです)
スクレイピングの実行は自己責任でお願いいたします。
※2025年現在、net競馬のサイト仕様の変更に伴い、下記の関数では正しくスクレイピングが出来ません。
生成AI等用いて調査し、下記ソースを編集して活用してください。
netkeibaからデータを取得するためには、PythonのライブラリであるBeautifulSoupとrequestsなどを使います。
この2つのライブラリを使うことで、ウェブページの情報を簡単に取得し、分析に役立てることができます。
まずは、必要なライブラリをインストールしましょう。
!pip install requests beautifulsoup4まずは必要なライブラリのインポートです。
import time
import requests
import pandas as pd
from bs4 import BeautifulSoup
import re
まずはレース結果をスクレイピングする関数です。
class RaceResultsScraper:
@staticmethod
def fetch_race_data(race_id_list):
race_results = {}
for race_id in race_id_list:
time.sleep(1) # リクエスト間隔を確保
race_id = str(race_id)
url = f"https://db.netkeiba.com/race/{race_id}"
response = requests.get(url)
response.encoding = "EUC-JP"
# DataFrameの読み込みと列名の修正
try:
df = pd.read_html(response.text)[0]
df.columns = df.columns.str.replace(' ', '') # 半角スペースの削除
except ValueError:
print(f"Failed to retrieve data for race_id: {race_id}")
continue # エラーハンドリング: DataFrameの取得に失敗した場合
# BeautifulSoupでHTMLを解析
soup = BeautifulSoup(response.text, "html.parser")
# 馬IDの取得
horse_id_list = []
try:
race_table = soup.find("table", summary="レース結果")
horse_links = race_table.find_all("a", href=re.compile("^/horse"))
for a in horse_links:
horse_id = re.findall(r"\d+", a["href"])
horse_id_list.append(horse_id[0])
except AttributeError:
print(f"Failed to retrieve horse data for race_id: {race_id}")
continue # エラーハンドリング: 馬IDの取得に失敗した場合
df["horse_id"] = horse_id_list
df.index = [race_id] * len(df)
race_results[race_id] = df
# 全てのレース結果を一つのDataFrameにまとめる
race_results_df = pd.concat(race_results.values())
return race_results_df次に出走馬の成績をスクレイプする関数です。
class HorseResultsScraper:
@staticmethod
def horse_race_data(horse_id_list):
horse_results = {}
for horse_id in horse_id_list:
time.sleep(1) # リクエスト間隔を確保
horse_id = str(horse_id)
url = f'https://db.netkeiba.com/horse/{horse_id}'
response = requests.get(url)
# DataFrameの読み込み
try:
df = pd.read_html(response.content)[3]
# 受賞歴がある場合のテーブル切り替え
if df.columns[0] == '受賞歴':
df = pd.read_html(response.content)[4]
except (ValueError, IndexError):
print(f"Failed to retrieve data for horse_id: {horse_id}")
continue # エラーハンドリング: DataFrameの取得に失敗した場合
# BeautifulSoupで血統表データの取得
try:
soup = BeautifulSoup(response.content, "html.parser")
blood_a_list = soup.find(class_="blood_table").find_all(
"a", href=re.compile("/horse/ped/")
)
except AttributeError:
print(f"Failed to retrieve blood data for horse_id: {horse_id}")
continue # エラーハンドリング: 血統情報の取得に失敗した場合
df.index = [horse_id] * len(df)
horse_results[horse_id] = df
# 全ての馬のレース結果を一つのDataFrameにまとめる
horse_results_df = pd.concat(horse_results.values())
return horse_results_dfコードの中身で何をしているのか理解するのは後で大丈夫です!
ひとまず実際にスクレイピングをしてみましょう!
関数を定義したので、あとは有馬記念のデータを集めるようにrace_idを調べましょう。
過去10年分の有馬記念のレースのrace_idは以下になります。
race_id_list = []
for year in range(2008, 2014, 1):
race_id = str(year)+ '06'.zfill(2) + '05'.zfill(2) + '08'.zfill(2) + '10'.zfill(2)
race_id_list.append(race_id)
race_id = "201406040810"
race_id_list.append(race_id)
race_id = "201506050810"
race_id_list.append(race_id)
race_id = "201606050910"
race_id_list.append(race_id)
for year in range(2017, 2023, 1):
race_id = str(year)+ '06'.zfill(2) + '05'.zfill(2) + '08'.zfill(2) + '11'.zfill(2)
race_id_list.append(race_id)
race_id_listこれで過去の有馬記念のrace_idをもった配列が出来ました。
いよいよ実際に関数を動かしてみましょう!
※warningが出力されるかもしれませんが特に気にしなくて大丈夫です。
R_result = RaceResultsScraper.fetch_race_data(race_id_list)R_result.head()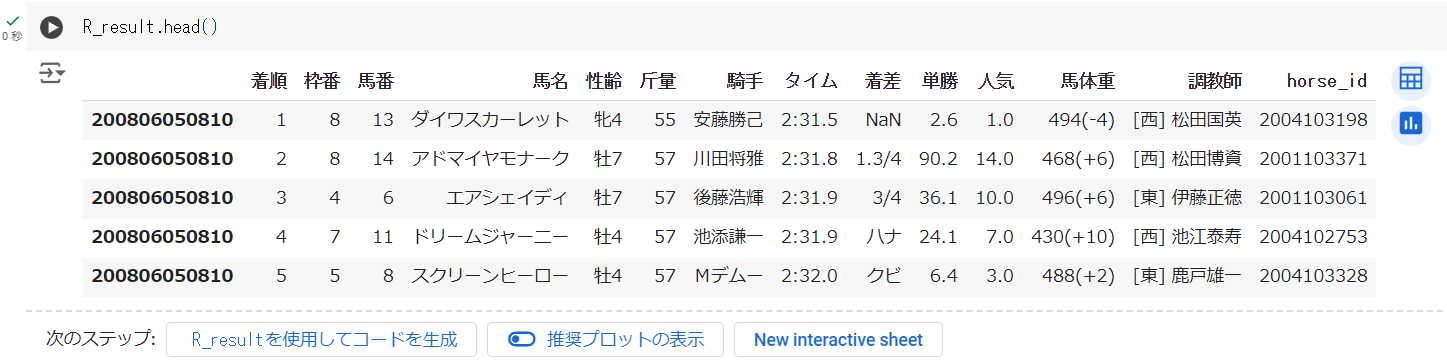
実行が終わり、このような表が出力されていれば成功です!
次に出走各馬のデータをスクレイプしましょう。
※出走馬は161頭いるため、実行完了まで5分程度時間がかかります
horse_id_list = R_result.horse_id.unique()
H_result = HorseResultsScraper.horse_race_data(horse_id_list)H_result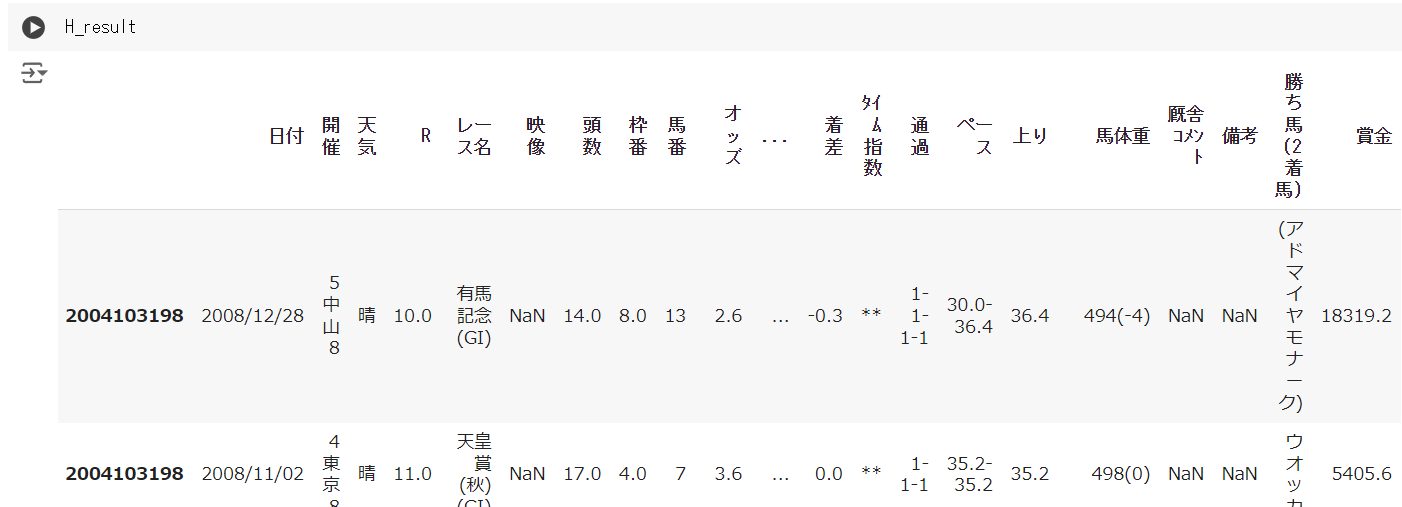
こちらも同様に表が出力されていれば成功です!
データが集まったので、drive内に保存しましょう。
 google colabを開いている状態で、左端のフォルダアイコンをクリックし、目のアイコンの隣のアイコンをクリックしてみましょう。
google colabを開いている状態で、左端のフォルダアイコンをクリックし、目のアイコンの隣のアイコンをクリックしてみましょう。
アクセスを許可するか聞かれた場合は、「Googleドライブに接続」をクリックし、認証に進んでください。
これで準備完了です!
あとは下記コードを実行して、先ほどの表を保存しましょう。
R_result.to_csv("/content/drive/MyDrive/arima.csv")H_result.to_csv("/content/drive/MyDrive/arima_horse.csv")パスの場所は自分でフォルダを作って好きなところを指定してもOKです!
よくわからないという方はこのまま実行しても問題ないです。
実行が終わると、保存した先のパスにcsvファイルが作られています。
これでデータの保存も完了です!
ひとまずここまでは言われるがまま、コードを実行してきた方も多いかもしれません。
今一度ここでどんなデータを集めたのか確認してみましょう!
まずはR_result(レースデータ)です。
以下のような要素が使えそうですね。
- 着順
- 馬番
- 性別、年齢
- 斤量
- 騎手
- タイム
- 単勝オッズ
- 馬体重
- 調教師
次にH_result(ホースデータ)です。
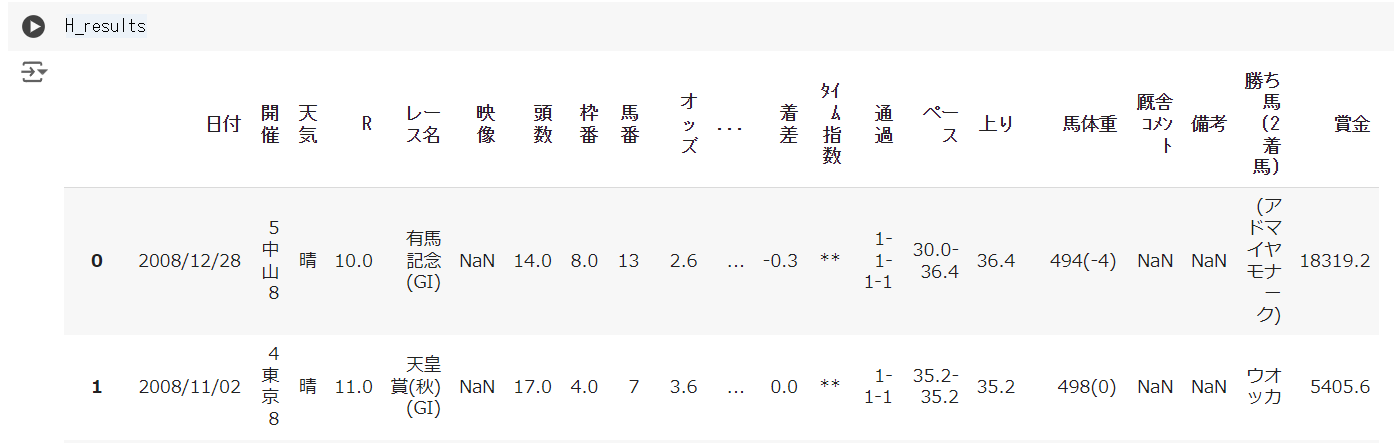
H_resultからは以下のような情報を得られそうですね。
- レース間隔
- どのコースが得意か(中山巧者など)
- 今までの上りタイム
- 獲得賞金額
- 脚質
みなさんが競馬を予想するときに見ているような情報は結構そろっているのではないでしょうか。
今回はこれらのデータから競馬予想モデルを作成したいと思います!
他にもデータ収集の方法を知りたい方はこちらの記事もご覧になってください。
③まとめ
これまでの前編では、競馬予測モデルを作成するための第一歩として、必要なデータの収集について解説しました。
重要なポイントを以下にまとめます。
- 効率的なデータ収集方法: スクレイピングを利用して、競馬関連のデータを効率的に収集する方法の学習
- スクレイピングの実践例: 実際のスクレイピングコードを用いて、Webからデータを自動で取得する方法を紹介
- 集めたデータの調査:スクレイピングしたデータで何を集めたか確認
データの収集が完了したら、次のステップではそのデータを前処理し、予測に有用な特徴量を作成する必要があります。
後編では、具体的なデータの前処理方法を解説し、どのようにしてデータを整理し、分析可能な状態にするかを学びます。
そして、最終的に予測モデルを構築し、そのモデルの精度を評価する方法についても説明します。
データサイエンスの実践的なスキルを身につけるための重要なステップを見逃さないように、ぜひ後編もご覧ください!

【初心者必見】競馬AI予測モデルをゼロから作成!簡単ステップとコードを大公開!-後編
-
- データの前処理: データをクリーンで分析しやすい形に整える方法
- 特徴量の作成: モデルの精度を高めるために必要な重要なデータポイントを選び出す技術
- 予測モデルの構築: 簡単なモデルを実際に作成し、その予測精度をチェックするプロセス


