 うまサイエンス
うまサイエンス はじめまして!さかなちゃんです!
「競馬予想AIモデルを自力で作ってみたい!」「予想を自動化させたい!」
前編がまだの方はこちら!

【初心者必見】競馬AI予測モデルをゼロから作成!簡単ステップとコードを大公開!-前編
今回も引き続きプログラミング初心者の方でも競馬予想モデルを作れるように、簡単に取り組めるAI競馬予測モデルの作成方法を紹介します!
データの収集から特徴量の作成、モデルの構築まで、初心者にも分かりやすく説明し、実際のコードも公開するのでぜひご覧になってください!
-
- データサイエンスの分野に興味がある!
- 競馬予想を自動化させたい!
- 競馬予想モデルを作りたい!
-
- Googleアカウント
- PC(スマホでもできなくはないけど操作難しいかも、、)
③データの前処理と特徴量作成

前回集めたデータを、機械がわかるように加工しましょう!
競馬予測モデルの精度を向上させるためには、データの前処理と特徴量の作成が不可欠です。
まずは集めたデータを読み込みましょう。
一応必要なライブラリのインポートも載せておきます。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as snsR_result=pd.read_csv("/content/drive/MyDrive/arima.csv")
H_result=pd.read_csv("/content/drive/MyDrive/arima_horse.csv")パスは自分で設定した方は変更してください。
これで集めたデータを読み込めました。
まずはR_result(レースデータ)をきれいにしましょう。
データは現状以下のような状態かと思います。
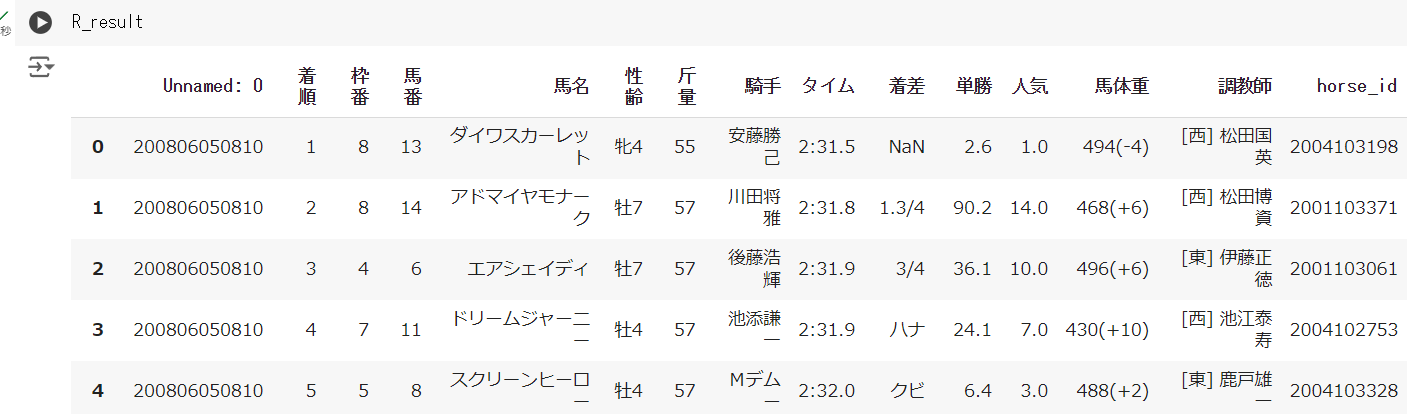
R_result.info()これでこのデータの情報を調べられます。以下のような出力がでます。
RangeIndex: 236 entries, 0 to 235
Data columns (total 15 columns):
# Column Non-Null Count Dtype
— —— ————– —–
0 Unnamed: 0 236 non-null int64
1 着順 236 non-null object
2 枠番 236 non-null int64
3 馬番 236 non-null int64
4 馬名 236 non-null object
5 性齢 236 non-null object
6 斤量 236 non-null int64
7 騎手 236 non-null object
8 タイム 232 non-null object
9 着差 217 non-null object
10 単勝 236 non-null object
11 人気 234 non-null float64
12 馬体重 236 non-null object
13 調教師 236 non-null object
14 horse_id 236 non-null int64
dtypes: float64(1), int64(5), object(9)
ここで見てほしいのは「int」や「object」と書いてあるところです。
機械学習モデルを作るためには、この中の「object」とあるものを数字に変換する必要があります。
また、中には出走取消している馬や、競争中止している馬のデータもあります。
今回はこれらのデータは取り除きましょう。ついでに数値データに変換します。
R_result=R_result[R_result['着順']!='取']
R_result=R_result[R_result['着順']!='中']
R_result['着順']=R_result['着順'].astype(int)次に「性齢」を「性別」と「年齢」に分けましょう。
R_result['性別']=R_result['性齢'].str[:1]
R_result['年齢']=R_result['性齢'].str[1:].astype(int)「馬体重」の情報も「体重」と「体重変動」に分けましょう。
R_result['体重']=R_result['馬体重'].str[:3].astype(int)
R_result['体重変動']=R_result['馬体重'].str[4:].str[-5:-1].astype(int)単勝オッズも今回は使用したいと思います。
また、その年の年度も情報として追加しましょう。
R_result['単勝']=R_result['単勝'].astype(float)
R_result['年度']=R_result['Unnamed: 0'].astype(str).str[:4].astype(int)これでR_resultはかなりきれいになりました!
同じようにH_result(ホースデータ)も整えましょう!
H_result['賞金'].fillna(0,inplace=True)
H_result=H_result[H_result['着 順']!='取']
H_result=H_result[H_result['着 順']!='中']
H_result=H_result[H_result['着 順']!='除']
H_result=H_result[H_result['着 順']!='失']
H_result=H_result.dropna(subset=['上り'])
H_result=H_result.dropna(subset=['ペース'])
H_result['日付']=H_result['日付'].str[:4].astype(int)
H_result=H_result.rename(columns={'Unnamed: 0': 'horse_id'})これで二つとも処理がしやすくなりました。
前処理をしたデータから特徴量を作成してみましょう。
そもそも特徴量ってなに?という方はこちらも参考にしてみてください。
主に処理が必要なのはH_resultのデータになります。
今回はH_resultからは出走馬の今までの最速の上りタイムと獲得賞金を使用したいと思います。
ここでは、あくまでその年の有馬記念の開催よりも前のデータを使用しないと正しくデータが処理できません。
競馬予想モデルを作る際は、未来の情報を使わないように注意しましょう!
- モデルには、レース前に既に知られているデータのみを使用する
- レース後の結果や統計情報を含めないようにする
- 未来の情報が含まれると、モデルの評価が不正確になり、実際の運用での信頼性が低下する
最速の上りタイムと獲得賞金を計算するために、R_resultとH_reultをくっつけましょう。
上記の未来のデータを取り込まないことを意識して処理をします。
merged_df=pd.merge(R_result,H_result,on='horse_id',how='left')
h_df1=merged_df[merged_df['年度']>merged_df['日付']]ふたつのテーブルが結合し、最速の上りタイムと獲得賞金を計算してR_resultに値を格納します。
for a in set(h_df1['Unnamed: 0']):#race_idごとに処理
df=h_df1[h_df1['Unnamed: 0']==a]
for b in set(df.horse_id):#出走馬のデータを計算
df1=df[df['horse_id']==b]
R_result.loc[(R_result['Unnamed: 0']==a) & (R_result['horse_id']==b),'上り最速']=df1['上り'][1:].min()
R_result.loc[(R_result['Unnamed: 0']==a) & (R_result['horse_id']==b),'獲得賞金']=df1['賞金'][1:].sum()これで計算できました!
データはかなりきれいになりましたが、先述の通り、機械学習モデルを作るためには、値を数字に変換する必要があります。
今回は「性別」のデータを数値に変換しましょう。
「性別」には {‘セ’, ‘牝’, ‘牡’} の3つの値があります。騙馬忘れがちですね。
今回は騙馬→1、牡馬→2、牝馬→3のように数字を振り分けましょう。
# 性別カラムの値を数字に置き換える
R_result['性別'] = R_result['性別'].replace({'セ': 1, '牡': 2, '牝': 3})このように、文字列のデータも数値データに変換することで、特徴量として使用することが出来ます。
④競馬予測モデルを作ろう!

データを整えたので、いよいよモデルの作成です!
モデル作成に必要なライブラリをインポートします。
import lightgbm as lgbこのモデルでは三着以内に入る確率を求めるモデルを作ってみましょう。
# 着順が3着以内なら1、それ以外なら0に変換
R_result['3着フラグ'] = np.where(R_result['着順'] <= 3, 1, 0)使用する特徴量は以下になります。
tokucyo_list=['年度','3着フラグ','馬番','斤量','単勝','性別','年齢','体重','体重変動','上り最速','獲得賞金']モデルを作るときは、学習用データとテストデータに分けて作成します。
もう少し詳しく知りたいかたはこちらをご覧になってください。
ここでは2020年を基準にデータを分割します。
train=R_result[tokucyo_list][R_result['年度']<=2020]
test=R_result[tokucyo_list][R_result['年度']>2020]ここまでやれば後はパソコンがんばれー!です。
もちろんパラメータの設定など、いじるところもありますが、基本的には成型したデータを用意してあげれば、簡単に機械学習モデルを作ることが出来ます!
# 説明変数と目的変数に分ける
x_train = train[tokucyo_list[2:]]
y_train = train['3着フラグ']
x_test = test[tokucyo_list[2:]]
y_test = test['3着フラグ']
# パラメータ設定
param = {
'num_leaves': 31,
'learning_rate': 0.1,
'n_estimators': 50,
'max_depth': 2,
'objective': 'binary', # 二値分類を指定
}
# LightGBMモデルの設定
lgbm = lgb.LGBMClassifier(**param)
# モデルの学習
lgbm.fit(x_train, y_train)# テストデータでの予測
test_predicted = lgbm.predict_proba(x_test)[:, 1]作ったモデルで、実際にテストデータがどのように予想されたのか確認してみましょう。
df=R_result[['着順','年度','人気','馬名']][R_result['年度']>2020] df['予想値']=test_predicted*100見やすいように、予想値を%の桁に変えています。
2021年の予想値を見てみると、1着のエフフォーリアや3着のクロノジェネシスが80%以上の確率で3着以内に来ると予測されましたね。
実際に2頭とも複勝圏内に入りました。
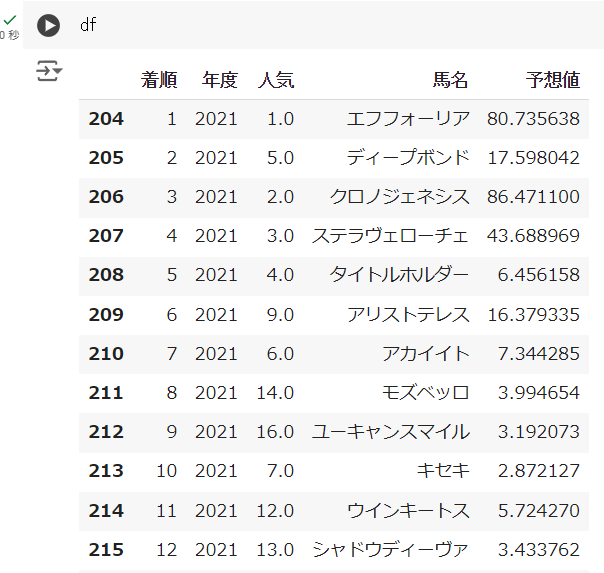
このように機械学習モデルは与えられたデータをもとに、値を出力します。
今作ったモデルはほんの一例です。
他にも騎手や、血統や、得意コースetc、、、予想するうえで使いたいデータは山ほどありますよね。
また予測値も、「オリジナルの指数を算出したい!」「穴馬を見つけたい!」など、目的によって求めたい値も変わってきます。
今回作成したモデルを元に、自分好みのモデルにぜひカスタマイズしてみてください!
⑤まとめ
後編では、競馬予測モデルを作成するための第一歩として、特徴量作成とモデルの作成について解説しました。
重要なポイントを以下にまとめます。
- データのクリーニング: 欠損値の処理や不要なデータの削除といったデータのクリーニング作業を行うことで、モデルの精度を向上させることができます。
- 有用な特徴量の選定: 予測に有用な特徴量を選定することが、予測精度を高めるために不可欠なステップです。
- シンプルなモデルから始め、予測精度を評価する: 初心者にとって、基本的なモデリングの流れを理解することで、より複雑なモデルへのステップアップに備えることができます。
ここまでお付き合いいただきありがとうございました!
本ブログでは競馬予想だけでなく、この記事のようにデータサイエンスの実践的なスキルを身につけるための記事も作成しております。
ぜひ他の記事もご覧ください!


